A dual-agent system that evaluates methodological transparency before the first reviewer opens your manuscript.
The problem we set out to solve
The biomedical reproducibility crisis is not a mystery. Its root causes have been catalogued for over a decade by the NIH, ARRIVE, CONSORT, and MDAR working groups: missing power analyses, unreported blinding procedures, unidentifiable antibodies, absent data availability statements. These are not failures of intellect. They are failures of reporting—gaps that slip through because nobody systematically checks.
The numbers bear this out. A large-scale automated analysis of nearly 1.6 million articles published in iScience found that fewer than 10% of papers reported blinding, under 10% included a power analysis, and antibody identifiability across the literature remained below 50%. The authors' Rigor and Transparency Index revealed no correlation between a journal's impact factor and its methodological transparency score—prestige does not predict rigor. The study also demonstrated that enforcement works: journals that actively enforced RRIDs saw antibody identifiability rates rise above 90%, compared to roughly 40% elsewhere.
The lesson is clear. Authors know what good methods reporting looks like. But without a mechanism to verify compliance, the majority of manuscripts arrive at peer review with significant gaps in methodological transparency. Human reviewers, already overburdened, cannot reasonably be expected to audit fifty sub-criteria across eight dimensions of rigor for every submission. The field needs infrastructure that can.
What we built
Today we are publicly describing the rigor review system running on manuscripts submitted to Alpha1Science. It is not a checklist PDF. It is not a reminder email. It is a fully automated, dual-agent evaluation pipeline that reads the full text of your paper and produces a structured, evidence-linked rigor assessment before your work enters peer review.
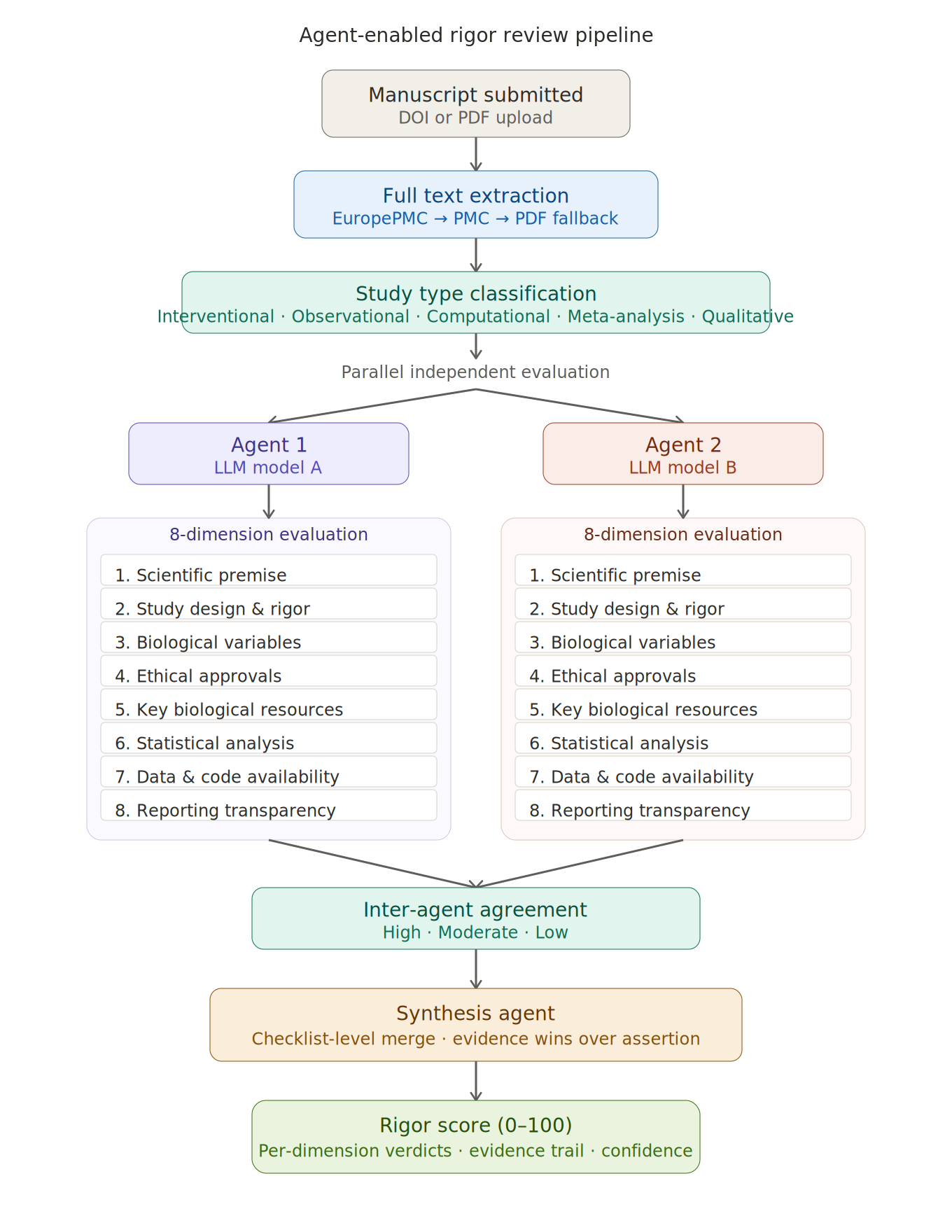
How it works
The system operates in five stages:
Full text extraction. When a manuscript is submitted via DOI or PDF upload, the system retrieves the complete text through EuropePMC, PubMed Central, or direct PDF parsing. If only an abstract is available, the system declines to score—rigor analysis requires the methods section, and we will not guess from an abstract.
Study type classification. The system first identifies what kind of study it is reading—interventional, observational, computational, meta-analysis, qualitative, case report, or mixed—because the criteria that matter differ by study type. A randomization check is essential for a clinical trial; it is not applicable to a bioinformatics pipeline. Penalizing papers for lacking elements their study design does not require would be noise, not rigor.
Parallel dual-agent evaluation. Two independent AI agents, running different foundation models, each evaluate the manuscript across eight dimensions derived from the NIH rigor and reproducibility framework, the MDAR checklist, ARRIVE 2.0, CONSORT, the RRID Initiative, and the SciScore/RTI criteria developed by Menke et al. The eight dimensions are:
Scientific premise and prior research
Study design and experimental rigor (randomization, blinding, power analysis, controls, replication)
Biological variables and subject characteristics (sex as a biological variable, demographics, species/strain)
Ethical approvals and consent (IRB, IACUC, informed consent, regulatory compliance)
Key biological and chemical resources (antibodies, cell lines, organisms, reagents, software—with RRID identification)
Statistical analysis and data reporting (named tests, assumptions, exact p-values, effect sizes, mathematical plausibility)
Data and code availability (repository deposits, accession numbers, code sharing)
Reporting completeness and transparency (methods sufficiency, guideline adherence, limitations, conflicts of interest)
Each dimension contains between three and nine sub-criteria. Each sub-criterion receives one of four ratings: reported and adequate, reported but inadequate, not reported, or not applicable. Every rating must be linked to specific textual evidence from the manuscript—a section, a sentence, a table footnote. If the agent cannot point to text, it must say "not reported." Fabricated evidence is architecturally prevented by the prompt design, and we validate outputs against the source text.
Critically, the system distinguishes not reported from problematic. A paper that does not mention mycoplasma testing may simply not use cell lines. A paper that mentions randomization but provides no method description is reported but inadequate. These are meaningfully different findings, and collapsing them would produce misleading scores.
Inter-agent agreement and synthesis. Once both agents complete their evaluations, the system computes agreement at the dimension level. Where agents agree, their shared judgment stands. Where they disagree, a third synthesis agent adjudicates—not by averaging, but by comparing evidence. The agent with more specific, verifiable textual citations wins, regardless of whether it gave the higher or lower rating. A "fail" verdict requires concrete evidence: a specific inconsistency, an impossible number, a demonstrably missing element. If only one agent flags a failure and its evidence is weak, the synthesis downgrades to a warning. Conversely, a "pass" must reflect genuine evidence of adequate reporting—absence of evidence of a problem is not the same as evidence of adequate reporting.
The synthesis operates at the checklist sub-criterion level, not just the top-level status, because two agents can agree on a dimension-level verdict while disagreeing on specific sub-criteria in ways that matter.
Deterministic scoring. The final score is computed from the synthesized verdicts using a fixed, auditable formula. Each applicable dimension receives 3 points for pass, 2 for warn, 1 for fail. Non-applicable dimensions are excluded. The sum is divided by the maximum possible score and scaled to 0–100. The calculation is recorded in full so it can be audited by authors and editors.
What the system is not
It is not a quality judgment on the science itself. A study can have a perfect rigor score and test a hypothesis that turns out to be wrong. Rigor review evaluates transparency and methodological reporting, not the importance or correctness of the findings. It cannot detect fraud, data fabrication, or conceptual errors. It reads what the authors wrote and checks whether what they wrote meets the reporting standards that the scientific community has converged on over the past decade.
It is not a replacement for peer review. It is a structured pre-screen that gives human reviewers a head start. When a reviewer opens a manuscript on Alpha1Science, they see—before reading a word—which methodological elements are present, which are partially addressed, and which are missing entirely. They can focus their expertise on the scientific substance rather than auditing whether the antibody catalog numbers are present.
Why two agents
A single model evaluating a paper has the same failure mode as a single reviewer: idiosyncratic blind spots. The dual-agent architecture was chosen because inter-rater reliability is the standard in human review, and the same logic applies to automated assessment. When two independent models, with different training data and different inference characteristics, examine the same text and arrive at the same conclusion, confidence is higher. When they disagree, the disagreement itself is informative—it identifies dimensions where the evidence is ambiguous or where the reporting is borderline.
The agreement metric (high, moderate, or low) is itself a signal to editors. A manuscript where both agents agree on all dimensions is straightforward. A manuscript with low agreement may warrant closer human attention—not because the agents failed, but because the reporting is genuinely unclear.
What changes for authors
Nothing about your writing process needs to change if you already follow established reporting guidelines. If you report the sex of your animals, name your statistical tests, cite your antibodies with RRIDs, describe your blinding procedure, and deposit your data with accession numbers, the system will find all of this and score it accordingly.
If your reporting has gaps—and the literature tells us that most papers do—you will see exactly where. The rigor report is not a rejection. It is a map. It shows you, before a reviewer ever sees your work, which of the established criteria you have addressed and which you have not. You can revise before review begins, strengthening your manuscript and saving everyone time.
What changes for reviewers
You gain structured prior information. Instead of starting from a blank page, you begin with a per-dimension breakdown of methodological reporting, each claim linked to specific passages in the manuscript. You can verify any rating by clicking through to the evidence. You can disagree—the system's assessment is advisory, never dispositive. But the systematic audit of forty-plus sub-criteria is done for you, freeing you to focus on the scientific questions that only a domain expert can evaluate.
The standards behind the system
The eight dimensions and their sub-criteria were not invented by us. They are drawn from:
NIH Rigor and Reproducibility guidelines (NOT-OD-15-103), which require grant applicants to address scientific premise, scientific rigor, relevant biological variables, and authentication of key resources.
The MDAR Framework (Materials, Design, Analysis, Reporting), a pan-publisher minimum reporting standard developed by editors from eLife, EMBO, PNAS, Science, Cell Press, PLOS Biology, and others, and published in PNAS.
ARRIVE 2.0, the updated guidelines for reporting animal research, with its Essential 10 minimum requirements.
CONSORT, the consolidated standards for reporting clinical trials.
The RRID Initiative, which provides persistent unique identifiers for antibodies, cell lines, organisms, and software tools.
The Rigor and Transparency Index developed by Menke, Roelandse, Ozyurt, Martone, and Bandrowski using SciScore, an automated tool that evaluated nearly 1.6 million articles and demonstrated that journal-level rigor scoring is feasible, informative, and uncorrelated with impact factor.
The EQUATOR Network, which catalogues discipline-specific reporting guidelines.
The Nature Checklist, whose implementation was shown by the NPQIP collaborative group to produce measurable improvements in rigor criteria reporting.
We did not pick favorites among these guidelines. We took the union of what has worked well. If a criterion appears in any of them, it is in our system, applied conditionally based on study type.
What comes next
This is version one. We intend to expand coverage to additional sub-criteria as the MDAR framework evolves, add support for discipline-specific guidelines beyond the life sciences, and integrate with preprint servers for automated scoring at the point of deposition. We are also exploring whether the per-dimension rigor data, aggregated across submissions, can serve as a journal-level or platform-level transparency metric—something the Rigor and Transparency Index demonstrated is both possible and valuable.
We believe that the quality of science depends on the quality of its reporting. Not because a well-reported study is always right, but because a poorly reported one cannot be evaluated at all. Agent-enabled rigor review is our contribution to closing that gap—not by adding more work for authors and reviewers, but by automating the structured verification that should have been infrastructure all along.
Alpha1Science · Platform Editorial
Rigor Review and Alpha1 Selection, together.
Create a free Αlpha¹ account to run manuscript Rigor Reviews, follow Alpha1 Selection, and participate in Formal Expert Review as a reviewer or author.